It is a common scenario to find table rows based on a free text search.
The typical example is a table (Test) with a clustered index on its Primary Key and a nonclustered index on the varchar column that we are interested in. Next, there is a query that searches all rows for a specific text.
For this example, table Test was filled with 2,241 rows, with an average of 71 characters in column t.
The specified query will return just 2 rows.
The typical example is a table (Test) with a clustered index on its Primary Key and a nonclustered index on the varchar column that we are interested in. Next, there is a query that searches all rows for a specific text.
CREATE TABLE Test (id int IDENTITY CONSTRAINT PK_Test PRIMARY KEY CLUSTERED ,t varchar(700) NOT NULL ,filler char(90) NULL ) CREATE INDEX IX_Test_t ON Test(t) SELECT * FROM Test WHERE t LIKE '%course%'
The specified query will return just 2 rows.
SQL Server 2000
Since we are not talking about Full Text Indexing, there are only two strategies for this query. The optimizer can either choose to scan the clustered index, or to scan the nonclustered index and look up all matching rows in the clustered index.The strategy to scan the nonclustered index only makes sense if the query returns just a few rows, because the nonclustered index is relatively large (about 50% of the size of the clustered index)
So this is what SQL Server 2000 does, regardless of the text we are looking for.
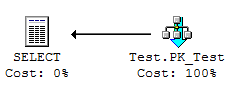
The clustered index is scanned, and its associated cost is 52 logical reads.
This is the safe query plan, and the best plan if the query returns more than a few rows. However, for this particular query - which returns only 2 rows - it would have been better to scan the nonclustered index.
SQL Server 2005
SQL Server 2005 introduces String Summary statistics. There are some specific requirements that determine whether the engine maintains this information, but basically they are created automatically when they could be useful.So let's check if String Summary information is available in our example.
DBCC SHOW_STATISTICS(Test,IX_Test_t)
Name Updated Rows Rows Sampled Steps Density Average key length String Index ---------- -------------------- ------ ------------- ------ ----------- ------------------- ------------ IX_Test_t Jul 20 2008 4:41PM 2241 2241 193 0.99199599 74.941544 YES
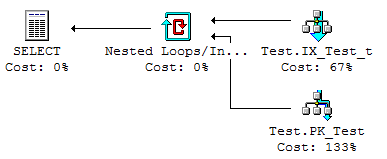
We see that the nonclustered index is scanned, and only the matching rows are looked up in the clustered index. The associated cost is 38 logical reads, which is 27% less than scanning the clustered index
If you know more...
This example shows how SQL Server 2005 will do better out-of-the-box then SQL server 2000. However, if you know that the query will only return a few rows, or if you are only interested in the first few rows, then there is a trick to help the optimizer: Simply make it a TOP (x) ... ORDER BY query!SELECT TOP 100 * FROM Test WHERE t LIKE '%course%' ORDER BY t
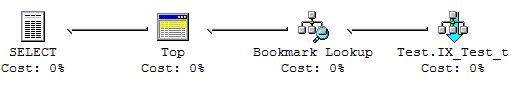
Now, the nonclustered index is scanned too, and the top 100 matches are looked up in the clustered index. The associated cost for this query: 41 logical reads.