With SQL, you specify a result. It is up to the RDBMS to get the result, and it can do that any which way
it wants, as long as the correct result is returned.
One interesting topic is the use of OR and AND in queries. In the situation of "@a = 3 OR @b = @c", if the engine knows that @a is 3, then it would not have to evaluate whether @b equals @c, because the result would be TRUE regardless of the second predicate
Similarly, in the situation of "@a = 3 AND @b = @c", if the engine knows that @a is not 3, then it would not have to evaluate whether @b equals @c, because the result would be FALSE regardless.
The best strategy of the optimizer would be to first evaluate the predicates with the lowest cost, before evaluating the predicates with higher cost. This article describes how the different versions of SQL Server optimize these types of situations.
Let's look at the first approach, with the first 2 IF command. Please note that all 5 IF commands in this article are all logically equivalent.
The key to lower and higher cost in these examples is the access to big_table, and more specifically, whether to do a quick index seek (column "indexed_column") or to scan the entire clustered index (column "non_indexed_column").
As you can see, the first predicate ("@a LIKE '%a%'") in example 1 checks whether @a contains an 'a' character.
If it does, the execution can be shortcut. The remaining predicates do not have to be evaluated, because the result will be TRUE.
If it is FALSE, then the next predicate will check the entire big_table to find a row. It will scan the entire clustered index, because we are looking for a value in a column that is not indexed. If it is found, the execution can be shortcut.
If no row is found, the last predicate will check big_table for a value in a column that is indexed.
The Example assumes that "WHERE indexed_column = 'does exist'" is TRUE, because that is the situation where optimization will give the greatest benefit. You can use the SQL script to create the big table and example data.
One interesting topic is the use of OR and AND in queries. In the situation of "@a = 3 OR @b = @c", if the engine knows that @a is 3, then it would not have to evaluate whether @b equals @c, because the result would be TRUE regardless of the second predicate
Similarly, in the situation of "@a = 3 AND @b = @c", if the engine knows that @a is not 3, then it would not have to evaluate whether @b equals @c, because the result would be FALSE regardless.
The best strategy of the optimizer would be to first evaluate the predicates with the lowest cost, before evaluating the predicates with higher cost. This article describes how the different versions of SQL Server optimize these types of situations.
Let's look at the first approach, with the first 2 IF command. Please note that all 5 IF commands in this article are all logically equivalent.
The key to lower and higher cost in these examples is the access to big_table, and more specifically, whether to do a quick index seek (column "indexed_column") or to scan the entire clustered index (column "non_indexed_column").
-- 1. Three OR'ed predicates
IF @a LIKE '%a%'
OR (@a NOT LIKE '%a%'
AND EXISTS (
SELECT *
FROM big_table
WHERE non_indexed_column = 'does not exist'
)
)
OR (@a NOT LIKE '%a%'
AND EXISTS (
SELECT *
FROM big_table
WHERE indexed_column = 'does exist'
)
)
-- 2. Three OR'ed predicates, cheapest predicate first
IF @a LIKE '%a%'
OR (@a NOT LIKE '%a%'
AND EXISTS (
SELECT *
FROM big_table
WHERE indexed_column = 'does exist'
)
)
OR (@a NOT LIKE '%a%'
AND EXISTS (
SELECT *
FROM big_table
WHERE non_indexed_column = 'does not exist'
)
)
As you can see, the first predicate ("@a LIKE '%a%'") in example 1 checks whether @a contains an 'a' character.
If it does, the execution can be shortcut. The remaining predicates do not have to be evaluated, because the result will be TRUE.
If it is FALSE, then the next predicate will check the entire big_table to find a row. It will scan the entire clustered index, because we are looking for a value in a column that is not indexed. If it is found, the execution can be shortcut.
If no row is found, the last predicate will check big_table for a value in a column that is indexed.
The Example assumes that "WHERE indexed_column = 'does exist'" is TRUE, because that is the situation where optimization will give the greatest benefit. You can use the SQL script to create the big table and example data.
In order processing
In SQL Server 7.0, the execution plans for these two IF commands are as follows.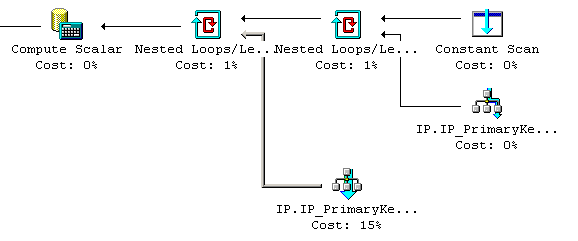
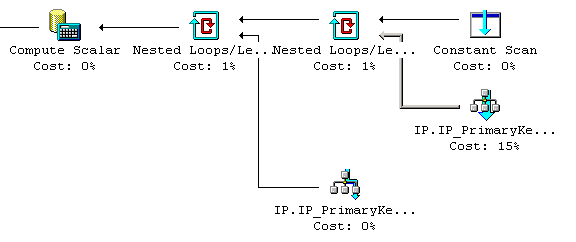
These query plans are very illustrative, because up to and including SQL Server 2012 nothing has changed.
First of all, if @a contains an 'a' character, then no version of SQL Server will ever access big_table.
That is the "Constant Scan" part of the query plan, and the "Nested Loops" that will never take place if @a has an 'a'.
However, is @a does not contain 'a', then one query will cause a fast query plan (where the index seek is performed, the 1st query plan), whereas the other query will lead to a slow query plan (where the whole clustered index is scanned first, the 2nd query plan).
In other words: if you write your query this way, then SQL Server will not always evaluate the cheapest predicate first, and you might end up with a suboptimal query plan.
Nesting
Here is the second approach. Instead of writing three predicates that are OR'ed, we'll write two expressions and the second expression breaks down into two expressions.
-- 3. Nested predicates
IF @a LIKE '%a%'
OR (@a NOT LIKE '%a%'
AND (
EXISTS (
SELECT *
FROM big_table
WHERE non_indexed_column = 'does not exist'
)
OR EXISTS (
SELECT *
FROM big_table
WHERE indexed_column = 'does exist'
)
)
)
-- 4. Nested predicates, cheapest predicate first
IF @a LIKE '%a%'
OR (@a NOT LIKE '%a%'
AND (
EXISTS (
SELECT *
FROM big_table
WHERE indexed_column = 'does exist'
)
OR EXISTS (
SELECT *
FROM big_table
WHERE non_indexed_column = 'does not exist'
)
)
)
However, the optimizer in SQL Server 2000 and 2008 is smarter. For both query 3 and 4, it will generate the same query plan; a query plan that will evaluate the lower cost predicate first (the one with the index seek).
This is the query plan in SQL Server 2000 for both query 3 and 4:
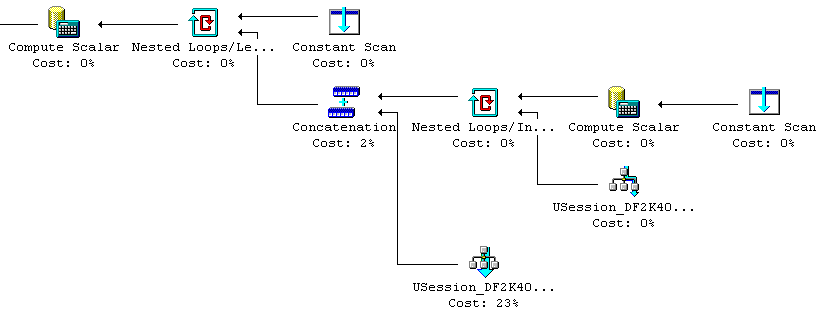
As mentioned above, SQL Server 2005 (9.00.4035.00) and SQL Server 2012 (11.0.3000.0) does not optimize this situation, whereas SQL Server 2000 (8.00.2040) and SQL Server 2008 (10.0.5500.0) does, which is unexpected.
As mentioned above, SQL Server 2005 (9.00.4035.00) and SQL Server 2012 (11.0.3000.0) does not optimize this situation, whereas SQL Server 2000 (8.00.2040) and SQL Server 2008 (10.0.5500.0) does, which is unexpected.
Optimizing yourself
If you know what would be the best order of evaluation, or if you are on SQL Server 2005 and cannot rely on the optimizer to make the best choice in this situation, you can force the exact order of evaluation using a CASE expression.
-- 5. Case expression, with cheapest predicate first
IF CASE WHEN @a LIKE '%a%' THEN 'true'
WHEN EXISTS (
SELECT *
FROM big_table
WHERE indexed_column = 'does exist' ) THEN 'true'
WHEN EXISTS (
SELECT *
FROM big_table
WHERE non_indexed_column = 'does not exist' ) THEN 'true'
END IS NOT NULL
By definition, in accordance with the SQL standard, the RDBMS has to evaluate the WHEN/THEN cases from top to bottom and must abort evaluation after handing the first successful WHEN/THEN case. And all SQL Server version adhere to that rule.
Below is the accompanying query plan in SQL Server 2005
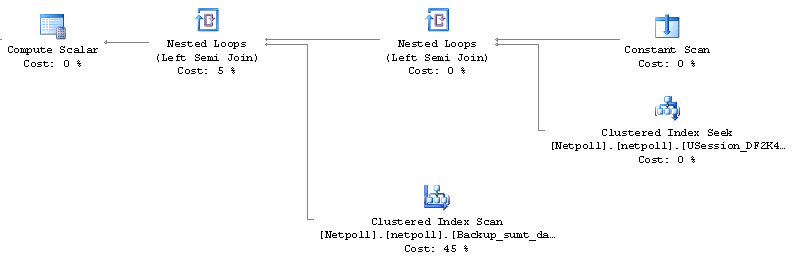
Conclusion
The optimization of (parts of) T-SQL commands is different from the optimization of SQL queries. SQL queries are better optimized. So if you have multiple EXISTS subqueries, it is best to combine them in one SQL statement, as shown in query 3 and 4 above.If you don't want to take any chances, you can find out yourself what the best order of execution is, and use a CASE expression to enforce order of evaluation.