When you create an index, you can choose between UNIQUE and NONUNIQUE. The default setting is NONUNIQUE,
so that is what you will get if you omit the UNIQUE keyword. Whenever you create a Primary Key
or Unique Constraint, SQL Server will automatically create a Unique Index to enforce unique keys.
There are a lot of advantages of a Unique Index compared to a Nonunique Index. This article describes these advantages, and should convince you to always declare the index to be UNIQUE if the data allows for that.
There are a lot of advantages of a Unique Index compared to a Nonunique Index. This article describes these advantages, and should convince you to always declare the index to be UNIQUE if the data allows for that.
Aggregates
If the index is unique, the optimizer knows there is a one-to-one relation between the indexed column and the Primary Key and can use this information in joins and aggregates.Suppose you have a table with internet domain names with a relation to a table with internet service providers, and you want to know the number of .com domains per internet service provider. That is what the query below does.
In the example, "Domeinen" represents the internet domains table, and "provider" the internet service providers table.
SELECT P.name, COUNT_BIG(*) AS "Number of .com domains"
FROM provider P
JOIN Domeinen D
ON D.isp_id = P.isp_id
WHERE D.reverse_domain LIKE REVERSE('%.com')
GROUP BY P.name
If there is no unique index on provider.name then the query plan looks like this
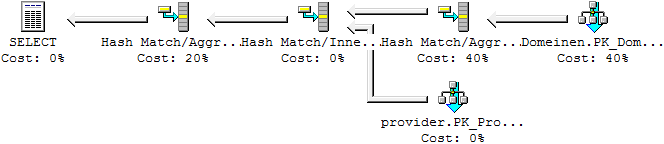
What does it do? It scans the Domeinen table for the all the domains that end with ".com". Next, the Hash Match/Aggregate counts the number of domains per isp_id. Next, the provider table is scanned and joined to the intermediate result with a Hash Match/Inner Join. Then another Hash Match/Aggregate totals the number of domains per provider.name
Now why does it do that last aggregation? Well, it has to, because we want to count the number of domains per provider, and there might be several providers with the same name. At least, that is what the database allows.
What does it do? It scans the Domeinen table for the all the domains that end with ".com". Next, the Hash Match/Aggregate counts the number of domains per isp_id. Next, the provider table is scanned and joined to the intermediate result with a Hash Match/Inner Join. Then another Hash Match/Aggregate totals the number of domains per provider.name
Now why does it do that last aggregation? Well, it has to, because we want to count the number of domains per provider, and there might be several providers with the same name. At least, that is what the database allows.
So let's add a Unique Constraint (or unique index) to this provider.name
ALTER TABLE provider ADD CONSTRAINT UQ_Provider_name UNIQUE (name)
Because of the unique index that is created to enforce the Unique constraint, the query plan now looks like this
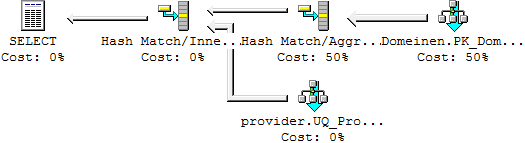
As you can see, there is only one Hash Match/Aggregate. There is no need for a second one, because since provider.name is unique, there is a one-to-one relation between isp_id and name, and the optimizer knows how to make smart use of it.
As you can see, there is only one Hash Match/Aggregate. There is no need for a second one, because since provider.name is unique, there is a one-to-one relation between isp_id and name, and the optimizer knows how to make smart use of it.
Wider Nonclustered Index
Internally, each index entry needs to have a unique key.Now, for the clustered index, there doesn't seem to be any negative effects if you don't declare it as unique. Only if the data isn't unique, the index will require extra space to store the so called uniquefier that is added to each nonunique index entry.
However, for a nonclustered index, it is a different matter.
If a nonclustered index is declared as unique, then only the leaf level of the index will include the row locator (either the clusterd index key or the RID). The rest of the index pages will only contain the index entries and pointers to other index pages. This way, the index is as narrow and shallow as possible. In other words, this way it will require the least amount of space, and it minimizes the number of steps to reach the row locator.
If the nonclustered index is not declared as unique, then the row locator is added to each index entry. This is done even if the data actually is unique. It is done even if SQL Server knows that the entries are unique (for example if it is a compound index that contains a unique column).
If the table has a clustered index, the row locator is the clustered index key. So the bigger the clustered index the more overhead this will add to a nonunique nonclustered index. Declaring a nonclustered index as unique can save up to 10% of the index size, and a few levels of the index depth.