Often, a developer creates a view that outer joins a "main" table with several reference tables.
If the query that uses such a view does not select columns from the outer joined table, is it then necessary for the database engine to access this table?
Let's set up an example and see.
Next, insert some rows in each table. I added approximately 130,000 rows to A, 20,000 rows to B, 40,000 rows to C and 40,000 rows to D.
Here are the queries that test SQL Server's behavior.
Please note, that views are expanded in the query that uses it. Therefore, the example below is the same as selecting from a view where you only select columns of the "main" table in the view.
As you can see, this query selects no columns from table B
If the query that uses such a view does not select columns from the outer joined table, is it then necessary for the database engine to access this table?
Let's set up an example and see.
-- "main" table CREATE TABLE A (id int PRIMARY KEY CLUSTERED ,b_id int NOT NULL ,c_id int NULL ) -- referenced table with Primary Key / Unique constraint CREATE TABLE B (id int PRIMARY KEY CLUSTERED ,description char(200) ) -- referenced table with Unique Index CREATE TABLE C (id int ,description char(200) ) CREATE UNIQUE CLUSTERED INDEX PK_C ON C(id) -- referenced table without Unique Index CREATE TABLE D (id int ,description char(200) )
Here are the queries that test SQL Server's behavior.
Please note, that views are expanded in the query that uses it. Therefore, the example below is the same as selecting from a view where you only select columns of the "main" table in the view.
SELECT A.* FROM A LEFT JOIN B ON B.id = A.b_id
SQL Server 7.0
So let's see what SQL Server 7.0 does: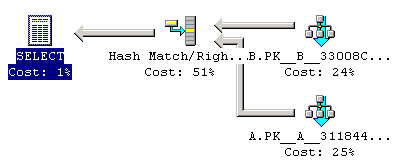
Table B is scanned. Table A is scanned. Then the results of B are Right Outer Joined with the results of A, using a Hash Match.
But why would it do that? We don't need data from B, and the optimizer could know that there is at most one match in table B for each row in table A. In other words, the outer join with B will never cause an increase in rows.
SQL Server 2000
SQL Server 2000 knows what to do with this query.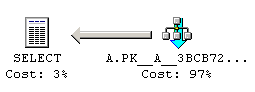
It scans table A, and that's it! The optimizer is now smart enough to figure out that it is pointless to retrieve data from B for this query.
Let's look at the next example.
SELECT A.* FROM A LEFT JOIN C ON C.id = A.c_id
Below is example 3.
SELECT A.* FROM A LEFT JOIN D ON D.id = A.c_id
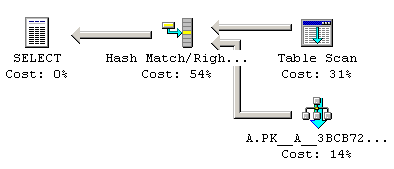
In this case, table D cannot be ignored. Because there might be two rows in D for the same id. And if that is the case, then the end result should have extra rows. It doesn't matter whether the id column is indexed or not. It doesn't matter whether the data is actually unique. All that matters is whether column id is declared as unique (Primary Key or Unique constraint), or that there is a Unique Index on it.
What if duplicate rows where not desired anyway?
SELECT DISTINCT A.* FROM A LEFT JOIN D ON D.id = A.c_id
SQL Server 7.0
How is the reaction to the added DISTINCT keyword in SQL Server 7.0:
Ouch! What is this all about? Let's get the simple (serial) plan, by adding OPTION (MAXDOP 1) to the query.
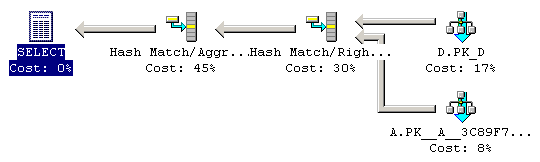
It extends the earlier line of reasoning. It actually outer joins table D using a Hash Match. Because of that, duplicate rows might have formed, so it uses another Hash Match to determine all distinct rows.
SQL Server 2000
How about SQL Server 2000?It does exactly the same as before. Since the primary key of A is part of the selection, and no columns of table D are selected, it knows it doesn't need to access D, and it knows are rows of A are unique (and therefore distinct)