In a batch, it is quite common to test if there are one or more matching rows, and act upon that.
There are several ways to do that. My personal favorite is to use EXISTS for that. For example:
This approach is very efficient. The engine will evaluate the table until it finds a row where Discount > 0
and stop searching. In the worst case situation it will have to scan the entire table, but in the best
case situation it might stop searching after the very first row.
Now some people use a different syntax. Either because they don't like to use EXISTS, or simply because they feel their syntax is more intuitive. One such often used syntax is this:
There are several ways to do that. My personal favorite is to use EXISTS for that. For example:
IF EXISTS ( SELECT * FROM "Order Details" WHERE Discount > 0 ) PRINT 'Some order lines have discount!'
Now some people use a different syntax. Either because they don't like to use EXISTS, or simply because they feel their syntax is more intuitive. One such often used syntax is this:
IF ( SELECT COUNT(*)
FROM "Order Details"
WHERE Discount > 0
) > 0
PRINT 'Some order lines have discount!'
SQL Server 2000
Up to (and including) SQL Server 2000, the optimizer will literally do what it is asked to do. It will evaluate all rows, count the number of rows that qualified, and then evaluate whether that number exceeds 0.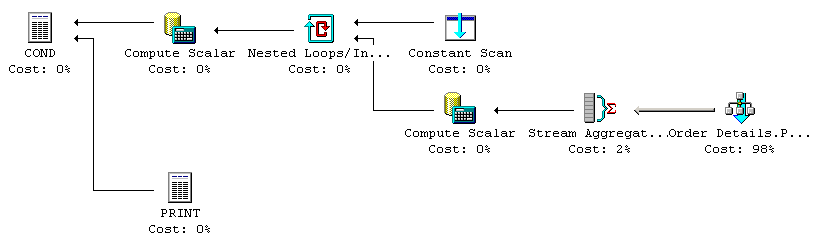
The table's clustered index is scanned. A Stream Aggregate is used to count the number of qualifying rows. The top line is all about the comparison "> 0".
SQL Server 2005
About the same query on SQL Server 2005's AdvertureWorks is this:
IF ( SELECT COUNT(*)
FROM Sales.SalesOrderDetail
WHERE UnitPriceDiscount > 0
) > 0
PRINT 'Some SalesOrderDetails have a discount!'
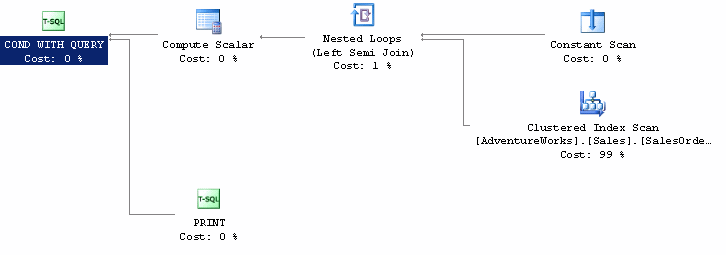
It still scans the table's clustered index, but it immediately aborts after the first match. Therefore, no full scan (unless there is no matching row), and no aggregate.