It started with a question from someone called BlackCatBone on the Microsoft SQL Server forum.
The case in question is a situation where a very large table stores money amounts with a currency
code. There is a second table with an exchange rate per currency code. Since 99% of all data would
be USD (which wouldn't require an exchange rate), BlackCatBone wondered if it was possible to improve
performance if the exchange rates table could only be joined for the non-USD currencies.
The answer is: yes, there are ways to take advantage of this skewed data distribution and to create a better performing "optional" join.
The answer is: yes, there are ways to take advantage of this skewed data distribution and to create a better performing "optional" join.
Setup
So here is the setup that will be used throughout the article. Table A represents the big transaction table with millions of rows. Table B represents the exchange rates.-- COLLATE only for SQL Server 2000 and up CREATE TABLE B (CurrencyCode char(3) COLLATE SQL_Latin1_General_CP850_BIN PRIMARY KEY CLUSTERED ,Currency varchar(50) ,ExchangeRate decimal(6,3) DEFAULT (0.63) ) CREATE TABLE A (ID int identity(1,1) PRIMARY KEY CLUSTERED ,Amount decimal(19,2) default (1) ,CurrencyCode char(3) COLLATE SQL_Latin1_General_CP850_BIN REFERENCES B ,filler char(40) )
You can find a script to populate these tables here. It will insert 164 rows in table B, and over 100 million rows in table A, with 99% USD currency.
The simplest query you can write to select all money amounts as US Dollars it this:
SELECT A.Amount * B.ExchangeRate FROM A INNER JOIN B ON A.CurrencyCode = B.CurrencyCode
Baseline query
But to make it easy to test this (we don't want to actually return a list of over 100 million rows), and to give a little headstart, this is the test query that will be the baseline to compare all other solutions against.SELECT AVG(CASE WHEN A.CurrencyCode = 'USD' THEN A.Amount ELSE A.Amount * B.ExchangeRate END) FROM A INNER JOIN B ON A.CurrencyCode = B.CurrencyCode OPTION (MAXDOP 1)
The CASE expression is used to apply the exchange rate only in cases where the currency is not US Dollars.
The query plan for this query is trivial, and the same on all versions (at least from SQL Server 7.0 thru 2008).
This query took approximately 93 seconds on the SQL Server 2008 test server. Obviously different servers (with different versions) has different performance, but for the purpose of this article, for each version, the performance of this query will the baseline of "100%".
Left Outer Join
The optimizer knows the distribution of the CurrencyCode values in table A. It can see that 99 percent of all rows are in USD. So the following query should give the optimizer enough information to come up with a more efficient query plan.SELECT AVG(CASE WHEN A.CurrencyCode = 'USD' THEN A.Amount ELSE A.Amount * B.ExchangeRate END) FROM A LEFT JOIN B ON A.CurrencyCode = B.CurrencyCode AND A.CurrencyCode <> 'USD' OPTION (MAXDOP 1)
Unfortunately, all versions basically come up with the same query plan (except that it is now using a Right Join instead of Inner Join).
So let's force a LOOP JOIN instead of a MERGE JOIN:
SELECT AVG(CASE WHEN A.CurrencyCode = 'USD' THEN A.Amount ELSE A.Amount * B.ExchangeRate END) FROM A LEFT LOOP JOIN B ON A.CurrencyCode = B.CurrencyCode AND A.CurrencyCode <> 'USD' OPTION (MAXDOP 1)
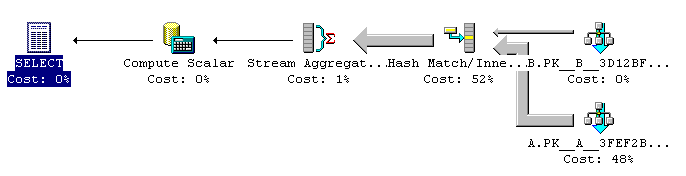
Now the differences show between different versions. The query plan of SQL Server 7.0 and 2000 is disappointing, because it will apply the "A.CurrencyCode <> 'USD'" predicate after looking up the matching row. In other words, all 100 million rows are matched against the exchange rate table.
The visual representation of the query plan in SQL Server 2000 does not really show that it performance worse than the baseline (approximately 4 times as slow), but the textual version of the plan does, see below:
|--Compute Scalar(...)
|--Stream Aggregate(...)
|--Nested Loops(Left Outer Join, OUTER REFERENCES:(A.CurrencyCode))
|--Clustered Index Scan(OBJECT:(A.PK__A__70963686))
|--Clustered Index Seek(OBJECT:(B.PK__B__6DB9C9DB),
SEEK:(B.CurrencyCode=A.CurrencyCode),
WHERE:(A.CurrencyCode<>'USD') ORDERED FORWARD)
As you can see, the Index Seek on table B is done for all rows of A. Only after it is found, it is ignored if the CurrencyCode in A happens to be non-US Dollar, which is too late to improve performance.
But as of SQL Server 2005, the optimizer comes up with exactly the query plan we would hope for.

And the textual version of the plan confirms this:
As you can see, the Startup Expression will make sure that only non-US dollar rows are looked up in B: an optional join!
In this test setup, the query syntax is approximately 6% faster than the baseline.
And the textual version of the plan confirms this:
|--Compute Scalar(...)
|--Stream Aggregate(...)
|--Nested Loops(Left Outer Join, OUTER REFERENCES:(A.CurrencyCode))
|--Clustered Index Scan(OBJECT:(A.PK__A__6322F9F4))
|--Filter(WHERE:(STARTUP EXPR(A.CurrencyCode<>'USD')))
|--Clustered Index Seek(OBJECT:(B.PK__B__60468D49),
SEEK:(B.CurrencyCode=A.CurrencyCode) ORDERED FORWARD)
As you can see, the Startup Expression will make sure that only non-US dollar rows are looked up in B: an optional join!
In this test setup, the query syntax is approximately 6% faster than the baseline.
Correlated Subquery
Another syntax that leads to NESTED LOOPS instead of HASH MATCH, is to write the query using a CASE expression (the one we already have) and use a correlated subquery to fetch the relevant exchange rate.
SELECT AVG(DisplayAmount)
FROM (
SELECT CASE WHEN A.CurrencyCode = 'USD' THEN A.Amount ELSE A.Amount * (
SELECT B.ExchangeRate FROM B WHERE B.CurrencyCode = A.CurrencyCode
) END AS DisplayAmount
FROM A
) T
OPTION (MAXDOP 1)
Here we basically see the same pattern.
SQL Server 7.0 will look up all rows in A, and use a Table Spool as a caching mechanism for B's rows.
This method isn't very effective. It takes more than twice the baseline performance.
SQL Server 2000 will also look up all rows in A, but instead uses a Hash Match as a caching mechanism for B's rows.
It turns out that this Hash Match / Cache is actually quite efficient. The query is between 13% and 26% faster than the baseline.
SQL Server 2005 and later shows this query plan:
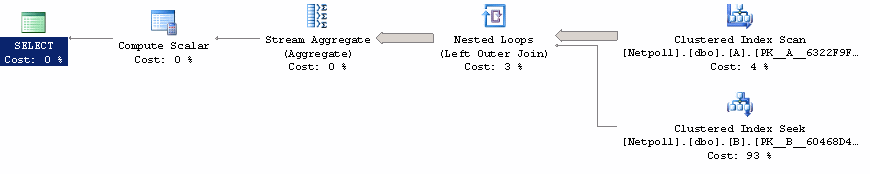
Again, the text version shows the good stuff:
|--Compute Scalar(...)
|--Stream Aggregate(...)
|--Nested Loops(Left Outer Join, PASSTHRU:(A.CurrencyCode='USD'), OUTER REFERENCES:(A.CurrencyCode))
|--Clustered Index Scan(OBJECT:(A.PK__A__6322F9F4))
|--Clustered Index Seek(OBJECT:(B.PK__B__60468D49),
SEEK:(B.CurrencyCode=A.CurrencyCode) ORDERED FORWARD)
This time, it is not called STARTUP EXPR but PASSTHRU, but it achieved the same goal: it makes sure that only the non-USD rows are looked up. This query is between 16% and 32% faster than the baseline performance.